


Experiments With RDFa
Posted by Brian Kelly on 3 May 2010
The Context
In a recent post I outlined some thoughts on Microformats and RDFa: Adding Richer Structure To Your HTML Pages. I suggested that it might now be timely to evaluate the potential of RDFa, but added a note of caution, pointing out that microformats don’t appear to have lived up to their initial hype.
Such reservations were echoed by Owen Stephens who considered using RDFa (with the Bibo ontology) to enable sharing of ‘references’ between students (and staff) as part of his TELSTAR project and went on to describe the reasons behind this decisions. Owen’s decision centred around deployment concerns. In contrast Chris Gutteridge had ideological reservations, as he “hate[s] the mix of visual & data markup. Better to just have blocks of RDF (in N3 for preference) in an element next to the item being talked about, or just in the page“. Like me, Stephen Downes seems to be willing to investigate and asked for “links that would point specifically to an RDFa syntax used to describe events?“. Michael Hausenblas provided links to two useful resources: W3C’s Linked Data Tutorial – on Publishing and consuming linked data with RDFa and a paper on “Building Linked Data For Both Humans and Machines” (PDF format). Pete Johnson also gave some useful comments and provided a link to recently published work on how to use RDFa in HTML 5 resources.
My Experiments
Like Stephen Downes I thought it would be useful to begin by providing richer structure about events. My experiments therefore began by adding RDFa markup for my forthcoming events page.
As the benefits of providing such richer structure for processing by browser extensions appear to be currently unconvincing my focus was in providing such markup by a search engine. The motivation is therefore primarily to provide richer markup for events which will be processed by a widely-used service in order that end users will receive better search results.
My first port of call was a Google post which introduced rich snippets. Google launched their support for Rich Snippets less than a year ago, in May 2009. They are described as “a new presentation of snippets that applies Google’s algorithms to highlight structured data embedded in web pages“.
Documentation on the use of Rich Snippets is provided on Google’s Webmaster Tools Web site. This provides me with information on RDFa (together with microdata and microformats) markup for events. Additional pages provide similar information on markup about people and businesses and organisations.
Although I am aware that Google have been criticised for developed their own vocabulary for their Rich Snippets I was more interested in carrying out a simple experiment with use of RDFa than continuing the debate on the most appropriate vocabularies.
The forthcoming events page was updated to contain RDFa markup about myself (name, organisation and location of my organisation, including the geo-location of the University of Bath.
For my talks in 2010 I replaced the microformats I have used previously with RDFa markup along the providing information on the date of the talks and their location (again with geo-location information).
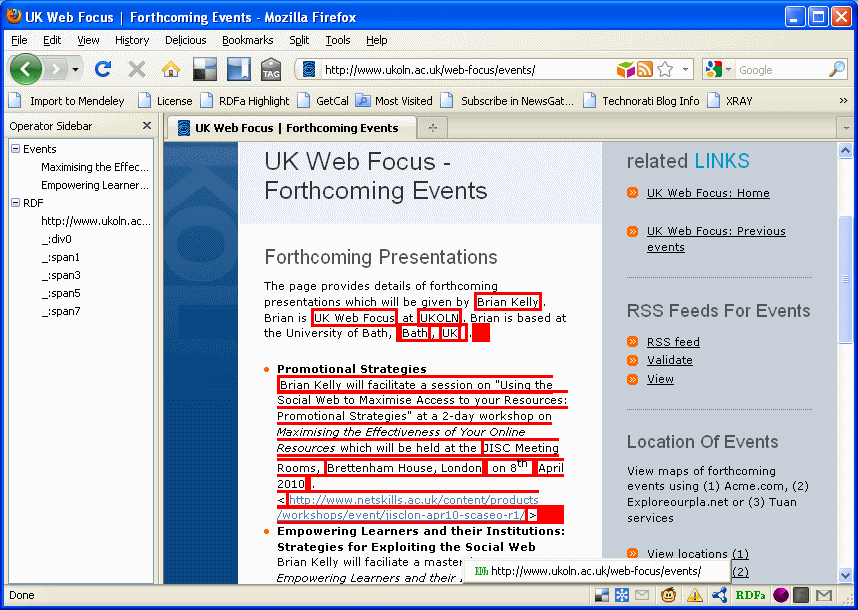
No changes where noticeable when viewing the page normally. However using FireFox plugins which display RDFa (and microformat) information I can see that software is able to identify the more richly structured elements in the HTML page. The screenshot shows how the markup was rendered by the Operator sidebar and the RDFa Highlight bookmarklet and, in the status bar at the bottom of the screen, links to an RDFa validator and the SIOC RDF Browser.

If you compare this image with the display of how microformats are rendered by the Operator plugin it will be noted that the display of microformats shows the title of the event whereas the display of RDFa lists the HTML elements which contain RDFa markup. The greater flexibility provided by RDFa appears to come at the price of a loss of context which is provided by the more constrained uses provided by microformats.
Is It Valid?
Although the HTML RDFa Highlight bookmarklet demonstrated that RDFa markup was available and indicated the elements to which the markup had been applied, there was also a need to modify other aspects of the HTML page. The DTD was changed from a HTML 1.0 Strict to:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN" "http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
If addition the namespace of the RDFa elements needed to be defined:
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:cc="http://creativecommons.org/ns#" xmlns:v="http://rdf.data-vocabulary.org/#" xml:lang="en">
It was possible for me to do this as I have access to the HTML page including elements defined in the HTML . I am aware that some CMS applications may not allow such changes to be made and, in addition, organisations may have policies which prohibit such changes.
On subsequently validating the page I discovered, however, HTML validity errors. It seems that my use of name="foo" attribute has been replaced by id="foo".
The changes to the DTD and the elements and the inclusion of the RDFa markup weren’t the only changes I had to make, however. I discovered that the id="foo attribute requires "foo" to start with an alphabetic character. I therefore had to change id="2010" to id="year-2010". This, for me, was somewhat more worrying as rather than just including new or slightly modified markup which was backwards-compatible, I was now having to change the URL of an internal anchor. If the anchors had started with an alphabetic character this wouldn’t have been an issue (and I would have been unaware of the problem). However it seems that a migration from a document-centred XHTML 1.0 Strict conforming world to the more data-centric XHTML 1.1+RDFa world may result in links becoming broken. I was prepared to make this change on my pages of forthcoming and recent events and change links within the pages. However if others are linking to these internal anchors (which I think is unlikely) then the links with degrade slightly (they won’t result in the display of a 404 error message; instead the top of the page will be displayed, rather than the entries for the start of the particular year).
Google’s View of the RDFa Markup
Using Google’s Rich Snippets Testing Tool it is possible to “enter a web page URL to see how it may appear in search results“. The accompanying image shows the output of this tool for my events page.

This shows the structure of the page which Google knows about. As Google knows the latitude and longitude for the location of the talk it can use this for location based services and it can provide the summary of the event and a description.
Is It Correct?
Following my initial experiment my former colleague Pete Johnston (now of Eduserv) kindly gave me some feedback. He alerted me to W3C’s RDFa Distiller and Parser service – and has recently himself published posts on Document metadata using DC-HTML and using RDFa and RDFa 1.1 drafts available from W3C.
Using the Distiller and Parser service to report on my event page (which has now been updated) I found that I had applied a single v:Event XML element where I should have used three elements for the three events. I had also made a number of other mistakes when I made use of the examples fragments provided in the Google Rich Snippets example without having a sound understanding of the underlying model and how it should be applied. I hope the page is now not only valid but uses a correct data model for my data.
I should add that I am not alone in having created resources containing Linked data errors. A paper on “Weaving the Pedantic Web” (PDF format) presented at the Linked Data on the Web 2010 workshop described an analysis of almost 150,00 URIs which revealed a variety of errors related to accessing and dereferencing resources and processing and parsing the data found. The awareness of such problems has led to the establishment of the Pedantic Web Group which “understand[s] that the standards are complex and it’s hard to get things right” but nevertheless “want[s] you to fix your data“. There will be a similar need to avoid polluting RDFa space with incorrect data.
Is It Worthwhile?
The experiences with microformats would seem to indicate that benefits of use of RDFa will be gained if large scale search engines support its use, rather than providing such information with an expectation that there will be significant usage by client-side extensions.
However the Google Rich Snippets Tips and Tricks Knol page state that “Google does not guarantee that Rich Snippets will show up for search results from a particular site even if structured data is marked up and can be extracted successfully according to the testing tool“.
So, is it worth providing RDFa in your HTML pages? Perhaps if you have a CMS which creates RDFa or you can export existing event information in an automated way it would be worth adding the additional semantic markup. But you need to be aware of the dangers of doing this in order to enhance findability of resources by Google since Google may not process your markup. And, of course, there is no guarantee that Google will continue to support Rich Snippets. On the other hand other vendors, such as Yahoo!, do seem to have an interest in supporting RDFa – so potentially RDFa could provide a competitive advantage over other search engine providers.
But, as I discovered, it is easy to make mistakes when using RDFa. So there will be essential to have an automated process for the production of pages containing RDFa – and there will be a need to ensure that the data model is correct as well as the page being valid. This will require a new set of skills as such issues are not really relevant in standard HTML markup.
I wonder if I have convinced Owen Stephens and Chris Gutteridge who expressed their reservations about use of RDFa? And are there any examples of successful use of RDFa which people know about?
“RDFa from Theory to Practice” Workshop Session
Note that if you have an interest in applying the potential of RDFa in practice my colleagues Adrian Stevenson, Mark Dewey and Thom Bunting will be running a 90 minute workshop session on “RDFa from theory to practice” at this year’s IWMW 2010 event to be held at the University of Sheffield on 12-14 July.

{kind=link}
Peter Barnes said
URL for Chris G’s latest thoughts on RDF: http://blogs.ecs.soton.ac.uk/webteam/2010/04/16/using-a-triplestore-instead-of-mysql-as-a-backend/
Owen Stephens said
I’m happy with the concept of using RDFa – and would have liked to use it in our project as previously mentioned. Unfortunately it looks like the issues we were concerned about are borne out by your experiments.
Our main use case was that we wanted to enable students (and others) to share references to bibliographic items (books/journals) in such a way that you could embed a structured version of the reference in an arbitrary web environment (which would enable reuse etc.) while displaying a human readable version in the page.
Specifically one environment where we wanted to enable this was within the Moodle VLE (http://moodle.org). This doesn’t (out of the box) serve pages as xhtml+rdfa – and changing this for a large implementation simply to get our single piece of functionality working wasn’t practical – and your experience with validation suggests that we might have easily created problems for ourselves if we had gone ahead with this.
Secondly we were concerned that there was a lack of consumer facing tools that would ‘consume’ the RDFa in a sensible way. Zotero (‘reference management’ software) was the only consumer tool we could find that had specific plans to do this. Obviously the fact that Google may make use of the information is a plus – but being indexed by Google wasn’t (in this case) a major use case.
Finally – to enable users to embed RDFa into any web environment means them being able to cut and paste (or drag and drop or other means) the items into that environment – so probably means support from popular html editors – while some tools may support this (e.g. I guess you could do this with dreamweaver), typical consumer level tools (such as the in page editors supported by WordPress, or other blogging platforms) don’t particularly support this (although I guess you could do it by changing to the html source mode). Anyway – it seemed that we were still a way off having something that ‘just worked’ for someone using these tools at a press and publish level.
So – I liked the idea of using RDFa, but we decided it just wasn’t there yet in terms of consumer usability and usefulness. My concern is that the adoption barrier will remain high unless serving pages as xhtml+rdfa becomes very very common for web publication platforms.
Experiences Migrating From XHTML 1 to HTML5 « UK Web Focus said
[…] facilitators and abstracts of the sessions themselves. As described in a post on Experiments With RDFa and shown in output from Google’s Rich Snippets Testing tool RDFa can be used to provide […]
Mark Greenfield - Higher Education Web Consulting » The Axe Man Commeth Preview #higheredlive said
[…] Experiences Migratin… on Experiments With RDFa […]
RDFa and WordPress « UK Web Focus said
[…] how does go about evaluating the potential of RDFa? Last year I wrote a post on Experiments With RDFa which was based on manual inclusion of RDFa markup in a Web page. Although this highlighted a […]