


The “Why Are We Not Boycotting Academia.edu?” Event
I recently came across a tweet which announced an event which addressed the question “Why Are We Not Boycotting Academia.edu?“. As described on the Eventbrite booking page:
With over 36 million visitors each month, the San Francisco-based platform-capitalist company Academia.edu is hugely popular with researchers. Its founder and CEO Richard Price maintains it is the ‘largest social-publishing network for scientists’, and ‘larger than all its competitors put together’. Yet posting on Academia.edu is far from being ethically and politically equivalent to using an institutional open access repository, which is how it is often understood by academics.
Academia.edu’s financial rationale rests on the ability of the venture-capital-funded professional entrepreneurs who run it to monetize the data flows generated by researchers. Academia.edu can thus be seen to have a parasitical relationship to a public education system from which state funding is steadily being withdrawn. Its business model depends on academics largely educated and researching in the latter system, labouring for Academia.edu for free to help build its privately-owned for-profit platform by providing the aggregated input, data and attention value.
The abstract concluded by summarising questions which will be address at the event, including:
- Why have researchers been so ready to campaign against for-profit academic publishers such as Elsevier, Springer, Wiley-Blackwell, and Taylor & Francis/Informa, but not against for-profit platforms such as Academia.edu, ResearchGate and Google Scholar?
- Should academics refrain from providing free labour for these publishing companies too?
- Are there non-profit alternatives to such commercial platforms academics should support instead?
The event was organised by The Centre for Disruptive Media and took place at Coventry University on 8 December 2015 from 3-6pm. Unfortunately I was not able to attend the event, but as this is an area of interest to me I thought I would publish this post, in which I argue that rather than boycotting Academia.edu we should make use it it (and similar services) by complementing institutional repository services with such services.
Background to My Interests
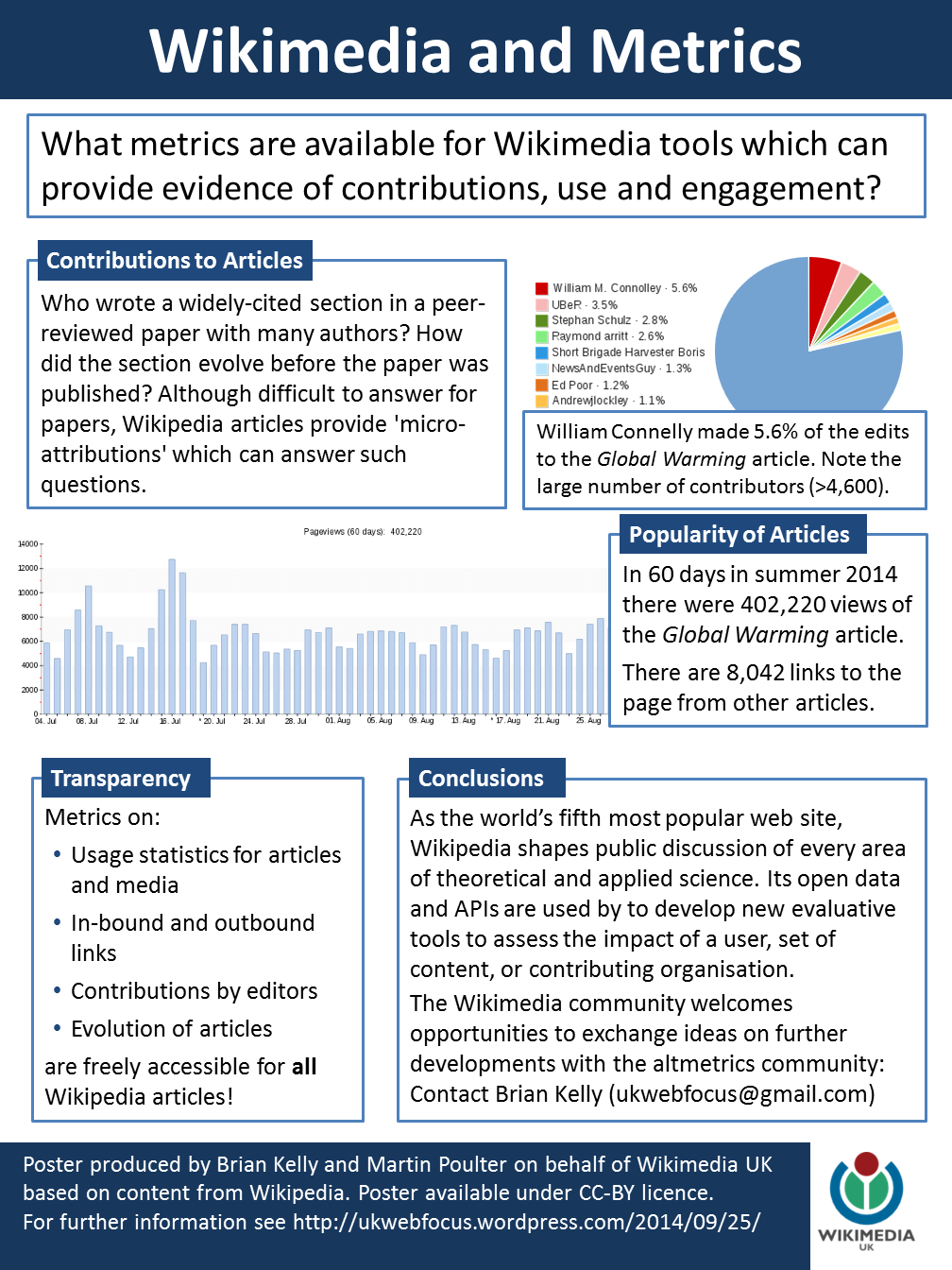
 Over a year ago I was invited to give a talk on “” at a symposium in Brussels on “How to Build an Academic Career” for the five Flemish universities. Over the past two years I have also given modified versions of the talk at the annual DAAD conference, the IRISS Research Unbound conference and for the iSchool@northumbria’s Research Seminar Series. As can be seen from the accompanying screenshot of one of the slides in the presentations I summarised the benefits which can be gained from making use of Academia.edu, based on personal experiences and recommending best practices.
Over a year ago I was invited to give a talk on “” at a symposium in Brussels on “How to Build an Academic Career” for the five Flemish universities. Over the past two years I have also given modified versions of the talk at the annual DAAD conference, the IRISS Research Unbound conference and for the iSchool@northumbria’s Research Seminar Series. As can be seen from the accompanying screenshot of one of the slides in the presentations I summarised the benefits which can be gained from making use of Academia.edu, based on personal experiences and recommending best practices.
My advice, as well as that provided by librarians and research support staff who promote use of social media by early career researchers, would appear to be in conflict with the general theme of the question “Why Are We Not Boycotting Academia.edu?” event. But rather than address the issue of whether universities should own the online services they use I will present evidence of how existing services are being used and the implications of such usage patterns.
What Does The Evidence Suggest?
Personal Experiences
The slides for my a talk on “” are available on Slideshare. In the talk I described the benefits of making one’s research content available in popular places, rather than restricting access to niche web sites such as institutional repositories. In particular I described the SEO benefits which can be gained by using popular sites which contain links to research papers which are hosted on an institutional repository. This advice was based on findings published in a paper which asked “Can LinkedIn and Academia.edu Enhance Access to Open Repositories?” by myself and Jenny Delasalle and presented at the Open Repositories 2012 conference.
 Interestingly I Googled for the paper using the search term “linkedin academia.edu researchgate opus” in order to find the copy of the paper hosted on Opus, the University of Bath institutional repository; however the first hit was for the copy hosted by Researchgate. This suggested that hosting a research paper on a popular service such as Academia.edu or, in this case, Researchgate, would provide better discoverability for Google than use of an institutional repository.
Interestingly I Googled for the paper using the search term “linkedin academia.edu researchgate opus” in order to find the copy of the paper hosted on Opus, the University of Bath institutional repository; however the first hit was for the copy hosted by Researchgate. This suggested that hosting a research paper on a popular service such as Academia.edu or, in this case, Researchgate, would provide better discoverability for Google than use of an institutional repository.
But since Google will remember previous searches a more objective tool to use would be Duckduckgo, which does not keep a record of previous searches. In this case the search for “linkedin academia.edu researchgate opus” found the paper hosted on Researchgate in second place. Using the full title of the paper, as shown the Duckduckgo search for “Can LinkedIn and Academia.edu Enhance Access to Open Repositories?” the order of the search results was (1) paper hosted by Academia.edu; (2) paper hosted by Opus instituional repository; (3) slides hosted on Slideshare and (4) paper hosted by Researchgate.
Personally. therefore, I have found benefits through use of Academia.edu and Researchgate in helping to raise the visibility of my research papers. But how popular in Academia.edu across the UK research sector?
Institutional Evidence
In order to answer this question a survey of Academia.edu use across the 24 Russell Group universities was carried out on 26 November 2015. The findings are given in the following table, with the link in the final column enabling the current results to be determined.
| Ref. no. | Institution | No. of People | Link |
| 1 | University of Birmingham | 5,408 | [Link] |
| 2 | University of Bristol | 5,759 | [Link] |
| 3 | University of Cambridge | 12,770 | [Link] |
| 4 | Cardiff University | 5,372 | [Link] |
| 5 | Durham University | 5,198 | [Link] |
| 6 | University of Exeter | 5,346 | [Link] |
| 7 | University of Edinburgh | 9,252 | [Link] |
| 8 | University of Glasgow | 6,094 | [Link] |
| 9 | Imperial College London | 3,943 | [Link] |
| 10 | King’s College London | 8,568 | [Link] |
| 11 | University of Leeds | 8,396 | [Link] |
| 12 | University of Liverpool | 4,911 | [Link] |
| 13 | London School of Economics | 6,184 | [Link] |
| 14 | University of Manchester | 11,249 | [Link] |
| 15 | Newcastle University | 4,756 | [Link] |
| 16 | University of Nottingham | 7,963 | [Link] |
| 17 | University of Oxford | 19,709 | [Link] |
| 18 | Queen Mary, University of London | 4,083 | [Link] |
| 19 | Queen’s University Belfast | 2,639 | [Link] |
| 20 | University of Sheffield | 4,821 | [Link] |
| 21 | University of Southampton | 5,646 | [Link] |
| 22 | University College London | 13,481 | [Link] |
| 23 | University of Warwick | 6,457 | [Link] |
| 24 | University of York | 5,297 | [Link] |
| Total | 173,301 |
Notes
- This information was collected on 9 December.
- The figures were obtained by entering the name of the institution and using the highest number listed. As can be seen from the accompanying image there may be other variants of the name of the institution: the figure shown with therefore give an under-estimation of the number of items related to the institution (the total given in the table is for the largest variant of the institution’s name i.e. 4,744 in this example).
Note that a post entitled A Survey of Use of Researcher Profiling Services Across the 24 Russell Group Universities published in August 2012 summarised usage of several researcher profiling services (Researchgate, ResearcherID, LinkedIn and Google Scholar Citations as well Academia.edu). The survey found 33,812 users of Academia.edu from the Russell Group universities, which suggested that there has been an increase of nearly 400% in just over 3 years.
Also note that the findings of a survey carried out in February 2013, which compared take-up of Academic.edu and Researchgate described in a post entitled Profiling Use of Third-Party Research Repository Services found that Researchgate appeared to have entries for 426,414 researchers from Russell Group Universities, compared with 39,546 for Academia.edu.
Discussion
My personal experiences, together with the institutional evidence of Academia.edu suggest that the service is popular with the user community. But what of the issues raised at yesterday’s meeting?

It seems to me that it will be difficult to find funding for the development of large-scale non-profit alternatives to commercial services such as Academia.edu and Researchgate. And even if funding to development and maintain the technical infrastructure was available, it may prove difficult to get researchers to see the benefits and make their research content available on a new, unproven service, espcially in light of evidence such as that provided in a paper on “Open Access Meets Discoverability: Citations to Articles Posted to Academia.edu” which described how:
Based on a sample size of 34,940 papers, we find that a paper in a median impact factor journal uploaded to Academia.edu receives 41% more citations after one year than a similar article not available online,50% more citations after three years,and 73% after five years.
Coincidentally a week ago I came across a tweet by Jon Tenant which stated that:
Reminder: @ResearchGate and @academia are networking sites, not #openaccess repositories http://bit.ly/1QWcGnD
As shown in the accompanying screenshot this tweet contained an image which highlighted some concerns regarding use of Academia.edu and Researchgate. However the first part of the tweet highlighted an important aspect of these services which are typically not provided by institutional repositories: @ResearchGate and @academia are networking sites.
It is worth expanding on this summary slightly, based n the evidence given above:
@ResearchGate and @academia are popular networking sites, with content likely to be more easily found using Google than content hosted on institutional repositories.
In addition the services may also enhance the visibility of resources hosted on institutional repositories:
Providing links from @ResearchGate and @academia to content hosted on institutional repositories should prpvide SEO benefits, and make the content of institutional repositories more easily found using search engines such as Google.
 This was the conclusion based on a survey published in the paper which asked “Can LinkedIn and Academia.edu Enhance Access to Open Repositories?“. Revisiting personal experiences use of the University of Bath’s Opus repository usage service it can be seen that my papers are the most-viewed of all researchers (and, interestingly, my formed UKOLN colleagues Alex Ball and Emma Tonkin are to be found in the top 5 researchers based on download statistics).
This was the conclusion based on a survey published in the paper which asked “Can LinkedIn and Academia.edu Enhance Access to Open Repositories?“. Revisiting personal experiences use of the University of Bath’s Opus repository usage service it can be seen that my papers are the most-viewed of all researchers (and, interestingly, my formed UKOLN colleagues Alex Ball and Emma Tonkin are to be found in the top 5 researchers based on download statistics).
This, of course, does not necessarily provide evidence of the quality of the papers; rather, as described in the paper cited above, it suggests that providing in-bound links from popular services will enhance the Google ranking of papers hosted by the repository.
Conclusions
Rather than developing open alternatives to Academia.edu and Researchgate my feeling is that the existing infrastructure of institutional repositories services such as Academia.edu and Researchgate can be used in conjunction, with the institutional repository providing the robust and secure management of content, with researcher profiling services providing SEO benefits in addition to the community benefits these social networking services can provide for researchers.
Such use of multiple services will also help address the risk of cessation of services, which is often highlighted as a risk of use of commercial services where there is no formal contractual agreement. It should be noted, of course, that sectoral not-for-profit services may also be closed down, as has happened with the Jorum OER repository service, whose closure Jisc announced in June 2015.
Of course when researchers leave their host institution they may wish to ensure that they continue to have full read/write access to their publications, in which case storing copies of the papers in the commercial services themselves will provide continued access after they have left their host institution and can no longer manage their publications – this, incidentally, was the approach I took after leaving UKOLN, University of Bath in July 2013.
I’d be interested to hear your thoughts on the relevance of commercial research profiling/repository services, whether the sector should look into providing open alternatives and the strategies needed to ensure that such approaches would be successful.



























")
")
")
















































")

")
















{kind=link}
You must be logged in to post a comment.